
https://www.acmicpc.net/problem/1167
◎ 문제

◎ 코드 및 풀이
첫번째 풀이
import java.util.*;
import java.io.*;
public class Main {
static int[][] arr;
static boolean[] visit;
static int n,max,total;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
n = Integer.parseInt(st.nextToken());
arr = new int[n+1][n+1];
visit = new boolean[n+1];
max = Integer.MIN_VALUE;
for(int i=0; i<n; i++) {
st = new StringTokenizer(br.readLine());
int index = Integer.parseInt(st.nextToken());
while(true) {
int a = Integer.parseInt(st.nextToken());
if(a==-1) break;
int b = Integer.parseInt(st.nextToken());
// mapArr[4][2] = 5 -> 4노드에서 2노드로 가는 길이는 5이다.
arr[index][a] = b;
}
}
for(int i=1; i<n+1; i++) {
total = 0;
dfs(i);
}
System.out.println(max);
}
static void dfs(int node) {
if(!visit[node]) {
visit[node] = true;
for(int j=1; j<n+1; j++) {
if(arr[node][j]!=0&&!visit[j]) {
total += arr[node][j];
max = Math.max(total, max);
dfs(j);
total -= arr[node][j];
}
}
}
}
}
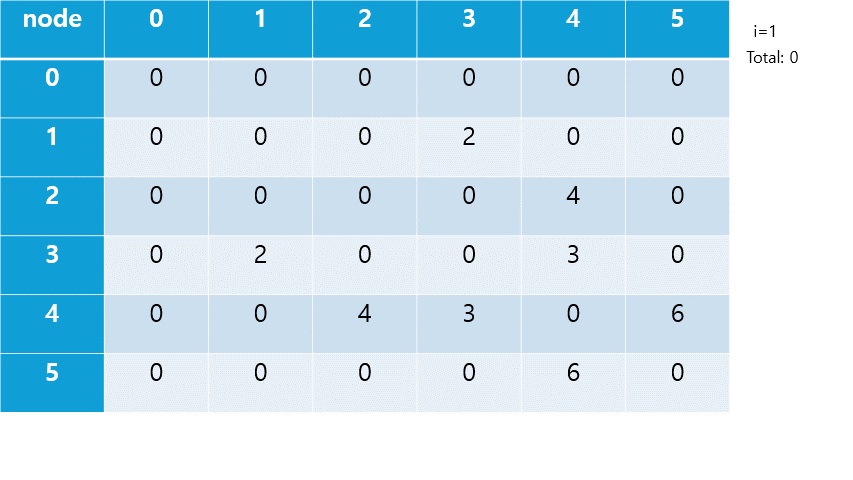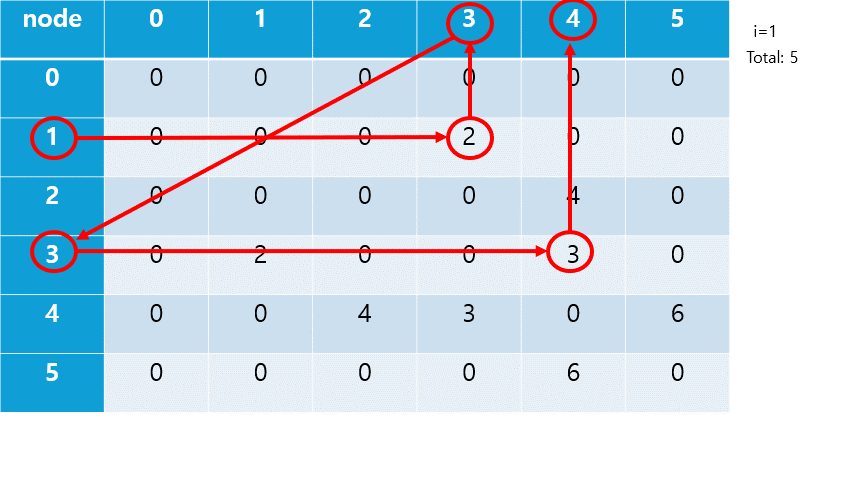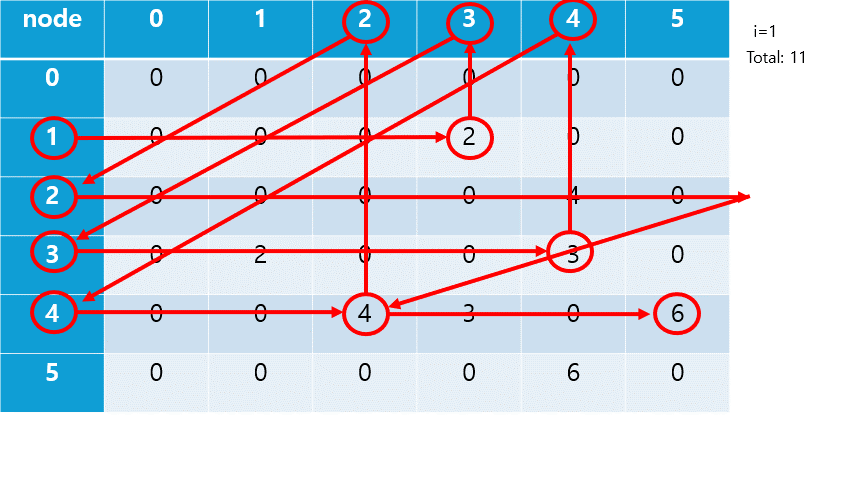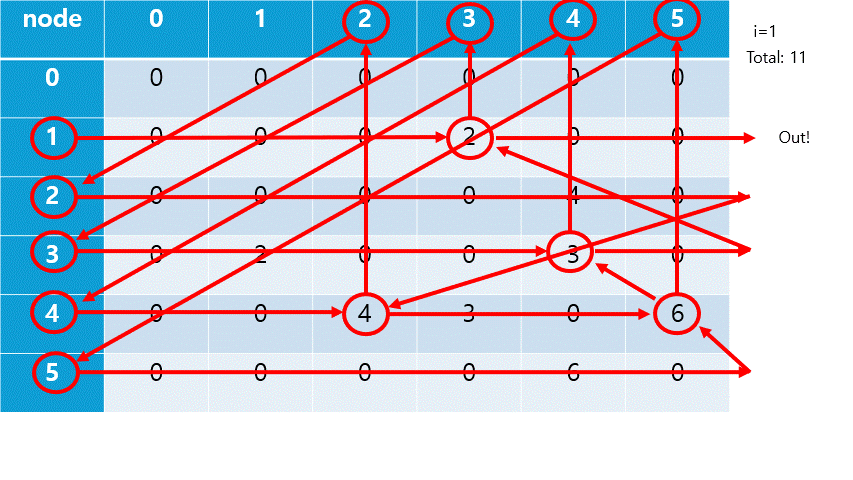
각 노드로부터 깊이 우선 탐색(DFS)을 진행해 간선 길이 합의 최대를 구한다.
첫 번째 풀이에서는 메모리 초과가 났다. n의 최대 크기는 100,000 이고 arr은 이차원 배열이기 때문에 arr 메모리의 최대 크기는 100,001 * 100,001 * 4bytes 로 약 40GB이다. 따라서 당연히 메모리 초과가 난다.
두번째 풀이
import java.util.*;
import java.io.*;
public class Main {
static List<ArrayList<Node>> list;
static boolean[] visit;
static int n,max;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
n = Integer.parseInt(st.nextToken());
list = new ArrayList<ArrayList<Node>>();
visit = new boolean[n+1];
max = Integer.MIN_VALUE;
for(int i=0; i<n+1; i++) {
list.add(new ArrayList<Node>());
}
for(int i=0; i<n; i++) {
st = new StringTokenizer(br.readLine());
int index = Integer.parseInt(st.nextToken());
while(true) {
int a = Integer.parseInt(st.nextToken());
if(a==-1) break;
int b = Integer.parseInt(st.nextToken());
Node node = new Node(a,b);
list.get(index).add(node);
}
}
for (int i = 0; i < n+1; i++) {
for (int j = 0; j < list.get(i).size(); j++) {
System.out.print("index: " + list.get(i).get(j).index+", value: "+list.get(i).get(j).value+" ");
}
System.out.println();
}
for(int i=1; i<n+1; i++) {
visit = new boolean[n+1];
dfs(i,0);
}
System.out.println(max);
}
static void dfs(int start, int length) {
if(!visit[start]) {
visit[start] = true;
for(Node node : list.get(start)) {
if(!visit[node.index]) {
length += node.value;
max = Math.max(length, max);
dfs(node.index,length);
length -= node.value;
}
}
}
}
static class Node {
int index;
int value;
Node(int index, int value){
this.index = index;
this.value = value;
}
}
}
두 번째 풀이에서는 불필요한 메모리를 없애기 위해 배열을 리스트로 바꾸고 향하는 노드와 간선의 길이를 사용하기 위해 노드 클래스를 만들어 리스트에 넣어줬다.
하지만 두 번째 풀이의 경우 모든 노드에서 부터 dfs 메서드를 사용하기 때문에 시간 초과가 발생한다.
세번째 풀이
import java.util.*;
import java.io.*;
public class Main {
static List<ArrayList<Node>> list;
static boolean[] visit;
static int n,max;
static int farNode;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
n = Integer.parseInt(st.nextToken());
list = new ArrayList<ArrayList<Node>>();
visit = new boolean[n+1];
max = Integer.MIN_VALUE;
for(int i=0; i<n+1; i++) {
list.add(new ArrayList<Node>());
}
for(int i=0; i<n; i++) {
st = new StringTokenizer(br.readLine());
int index = Integer.parseInt(st.nextToken());
while(true) {
int a = Integer.parseInt(st.nextToken());
if(a==-1) break;
int b = Integer.parseInt(st.nextToken());
Node node = new Node(a,b);
list.get(index).add(node);
}
}
// 임의의 노드(1~n)에서부터 가장 먼 노드를 찾고 farNode에 해당 노드의 인덱스를 저장
dfs(1,0);
// 저장된 farNode에서 부터 가장 먼 노드의 탐색 결과를 구한다.
visit = new boolean[n+1];
dfs(farNode,0);
System.out.println(max);
}
static void dfs(int start, int length) {
if(!visit[start]) {
visit[start] = true;
for(Node node : list.get(start)) {
if(!visit[node.index]) {
length += node.value;
/* max = Math.max(length, max); */
if(max<length) {
max = length;
farNode = node.index;
}
dfs(node.index, length);
length -= node.value;
}
}
}
}
static class Node {
int index;
int value;
Node(int index, int value){
this.index = index;
this.value = value;
}
}
}
두 번째 풀이에서의 패착은 dfs 메서드가 불필요하게 많이 실행된다는 점이었다. 1부터n까지 메서드를 실행시켰기 때문에 시간초과가 발생했다.
트리의 특징을 살펴보면 어떠한 점에서 시작하던지 간선의 길이가 최대인 노드를 찾는다면 과정을 수행한다면 그 탐색의 마지막에 탐색된 노드는 전체 트리를 놓고 봤을 때도 전체의 최대를 구하는 결과에서의 시작 노드이거나 끝 노드일 수 밖에 없다. 따라서 임의의 한 점에서 dfs를 실행하고 마지막 노드의 번호를 저장해둔다. 그리고 다시 한번 저장된 노드에서부터 dfs를 실행하면 반드시 트리 전체의 지름이 나온다.

◎ 기록
메모리와 시간 둘 다 잡아야 하는 문제였다. 오랜만에 진득하게 고민하고 생각해볼 수 있는 시간이었다. dfs문제는 많이 보다 보니 감이 어느정도 잡혀가고 있는 것 같다.
'코테' 카테고리의 다른 글
| [백준 / Java] 1043번 : 거짓말 (0) | 2024.05.08 |
|---|---|
| [프로그래머스 / Java] Lv.1 끝! (0) | 2024.02.28 |
| [프로그래머스 / Java] 실패율 (0) | 2024.02.22 |
| [프로그래머스 / Java] 점프와 순간이동 (0) | 2023.09.07 |
| [프로그래머스 / Java] 짝지어 제거하기 (0) | 2023.08.28 |